目录
ELK
概念
1、ELK是三个单词的缩写
elasticsearch logstash kibana
2、ELK的作用是日志收集的
传统方式的ELK大概分为以下几步:
shell日志收集 #logstash(重量级的不用他) 日志存储 #ES 日志分析 #ES(可以用来做搜索引擎)分词原理 日志展示 #kibana 节点收集 #filebeat
3、为什么收集日志?
shell1、业务分析 2、大数据获取到数据 3、由人工智能的算法推送 4、故障排查
4、浅说行为追踪流程
shellELK给大数据平台提供数据
大数据平台分析数据,将分析的结果,给智能推荐系统
智能推荐系统,给用户推荐产品/信息
#智能推荐系统的核心是推荐算法
5、ELK收集日志的三种架构:
1、ES + Logstash + Kibana
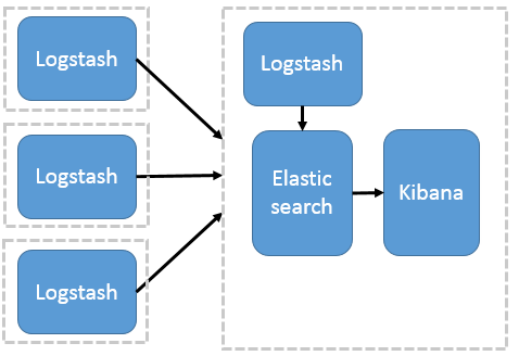
shell#此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
#这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患
2、ES + Logstash + filebeat + Kibana
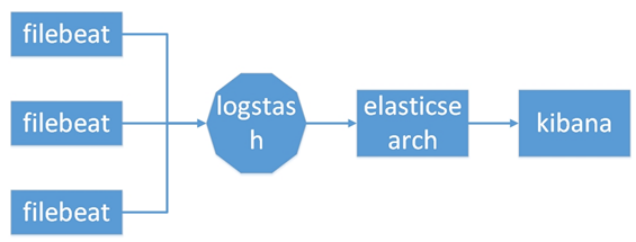
shell#与上一种架构相比,这种架构增加了一个filebeat模块。filebeat是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较logstash), 所以生产中,往往会采取这种架构方式,此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。但是这种架构有一个缺点,没有消息队列缓存,当logstash出现故障,会造成日志的丢失。
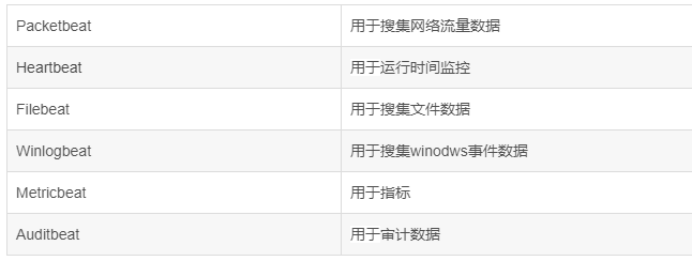
轻量级日志采集框架Beats,其中包含以下6种:
3、ES + Logstash + filebeat + redis(kafka)+ Kibana
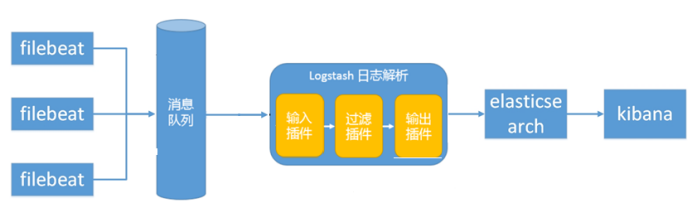
说明:
logstash节点和elasticsearch节点可以根据日志量伸缩节点数量, filebeat部署在每台需要收集日志的服务器上。
此种架构引入了消息队列机制,位于各个节点上的beats先将数据/日志传递给消息队列(kafka、redis、rabbitMQ等),logstash从消息队列取数据进行过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
注:Beats还不支持输出到消息队列,新版本除外:5.0版本及以上
工作流程:Filebeat采集—>发到kafka—> logstash处理从kafka缓存的数据进行分析—> 输出到es—> 显示在kibana
-
多个独立的agent(filebeat)负责收集不同来源的数据,一个中心agent(logstash)负责汇总和分析数据,在中心agent前的Broker(使用kafka/redis实现)作为缓冲区,中心agent后的ElasticSearch用于存储和搜索数据,前端的Kibana提供丰富的图表展示。
-
filebeat表示日志收集,使用filebeat收集各种来源的日志数据,可以是系统日志、文件、redis、mq等等;
-
Broker作为远程agent与中心agent之间的缓冲区,使用kafka/redis实现,一是可以提高系统的性能,二是可以提高系统的可靠性,当中心agent提取数据失败时,数据保存在kafka/redis中,而不至于丢失;
-
中心agent也是LogStash,从Broker中提取数据,可以执行相关的分析和处理(Filter);
-
ElasticSearch用于存储最终的数据,并提供搜索功能;
-
Kibana提供一个简单、丰富的web界面,数据来自于ElasticSearch,支持各种查询、统计和展示。
shell#这种模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性
ELK基础架构与安装
一、ELK有两种安装方式
-
集成环境:Logstash有一个集成包,里面包括了其全套的三个组件;也就是安装一个集成包。
-
独立环境:三个组件分别单独安装、运行、各司其职。(比较常用)
二、官方地址
三、ELK环境部署
ES+Logstash+Kibana=ELK
- 首先把服务器时间和外部服务器同步
shell[root@elk ~]# ntpdate ntp1.aliyun.com 1 Jul 10:51:54 ntpdate[58439]: step time server 120.25.115.20 offset -0.684184 sec [root@elk ~]#
- 上传需要的安装包

shell[root@elk ~]# ll total 860696 -rw-r--r--. 1 root root 284513057 Aug 19 2019` elasticsearch-7.3.0-linux-x86_64.tar.gz -rw-r--r--. 1 root root 190890122 Jun 16 2018` jdk-8u171-linux-x64.tar.gz -rw-r--r--. 1 root root 234174592 Aug 19 2019` kibana-7.3.0-linux-x86_64.tar.gz -rw-r--r--. 1 root root 171765594 Aug 19 2019` logstash-7.3.0.tar.gz [root@elk ~]#
- 准备工作完毕,开始安装!
1、部署JDK环境
shell[root@elk ~]# tar -xf jdk-8u171-linux-x64.tar.gz -C /usr/local/
#将JDK包解压到/usr/local/下
- 将JDK的变量文件写入到/etc/profile文件中
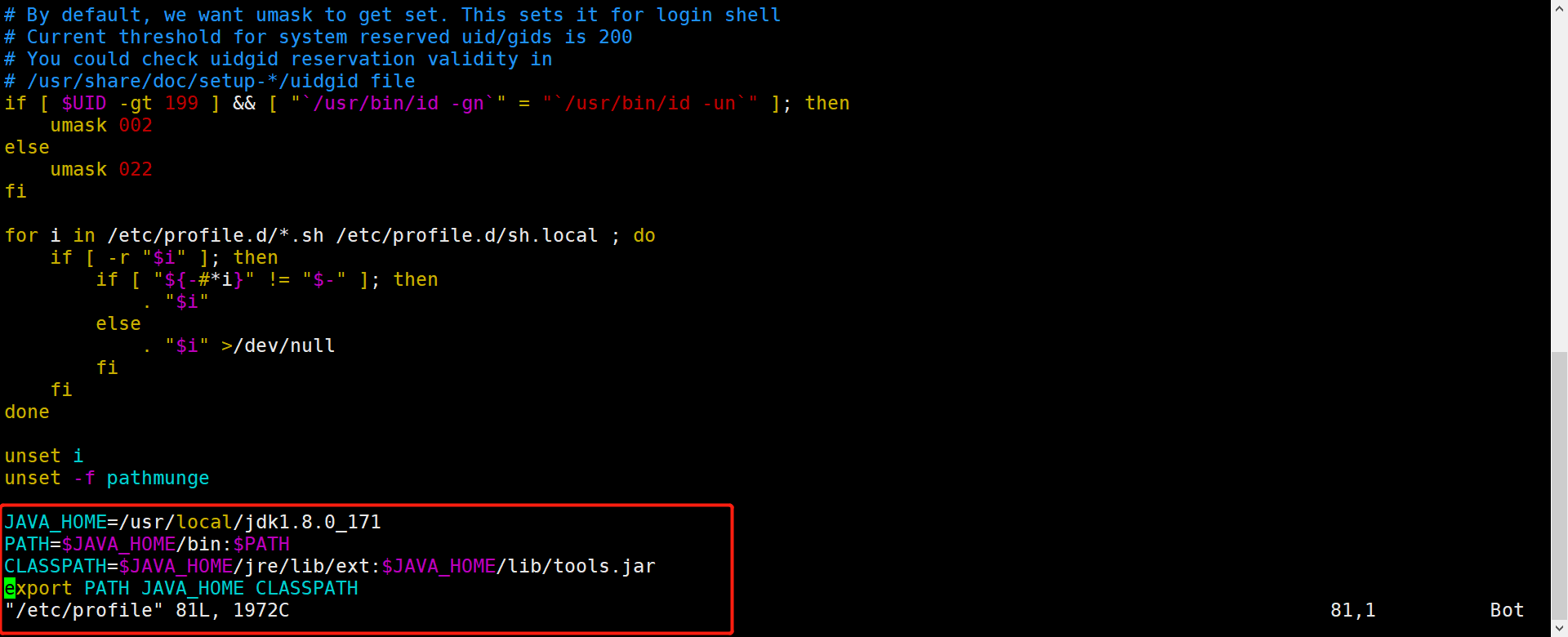
shellJAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
#写好后使其生效
[root@elk ~]# source /etc/profile
#测试是否生效
[root@elk ~]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@elk ~]#
2、安装ES
-
我们这里开始安装Elasticsearch,这里做实验配置用的是Elasticsearch单节点部署,生产环境中应该部署Elasticsearch集群,保证高可用。
-
解压ES安装包
shell[root@elk ~]# tar -xf elasticsearch-7.3.0-linux-x86_64.tar.gz -C /usr/local/
#将ES的包解压到/usr/local/下
- 创建ELK用户,将es目录属主和属组都设为ELK
shell#创建用户
[root@elk ~]# useradd elk
#给ES目录授权
[root@elk ~]# chown -R elk.elk /usr/local/elasticsearch-7.3.0/
-
**设置内核参数,保证有足够大的空间是ELK能正常运行 **
shell[root@elk ~]# cat /etc/sysctl.conf | egrep -v "#|^$" vm.max_map_count=655360 [root@elk ~]# #这条配置是表示一个进程能够占用虚拟内存的最大值 -
**设置文件最大打开数和进程最大打开数 **
shell[root@elk ~]# cat /etc/security/limits.conf | egrep -v "#|^$"
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
[root@elk ~]#
#nofile是文件最大打开数
#soft是软限制 hard是硬限制
- 切换到ELK用户,并修改配置文件
shell[root@elk ~]# su elk
[elk@elk root]$ cd /usr/local/elasticsearch-7.3.0/config/
[elk@elk config]$ ls
elasticsearch.keystore log4j2.properties roles.yml users_roles
elasticsearch.yml jvm.options role_mapping.yml users
[elk@elk config]$ cp elasticsearch.yml{,.bak}
elasticsearch.keystore elasticsearch.yml.bak log4j2.properties roles.yml users_roles
elasticsearch.yml jvm.options role_mapping.yml users
#修改配置文件
17行` cluster.name: my-application `#集群名称,同一个集群的标识
23行` node.name: elk-1 `#节点名称
33行` path.data: /data/elk/data `#数据存储位置
37行` path.logs: /data/elk/logs `#日志文件的路径
45行` bootstrap.memory_lock: false
46行` bootstrap.system_call_filter: false
57行` network.host: 0.0.0.0 `# ES的监听地址,这样别的机器也可以访问
61行` http.port: 9200 `#监听端口,ES节点和外部通讯使用,默认的端口号是9200
74行` cluster.initial_master_nodes: ["elk-1"] `#设置一系列符合主节点条件的节点的主机名或IP地址来引导启动集群。
shell#修改后如下
[elk@elk config]$ egrep -v "#|^$" elasticsearch.yml
cluster.name: my-application
node.name: elk-1
path.data: /data/elk/data
path.logs: /data/elk/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["elk-1"]
[elk@elk config]$
-
切换到root用户创建数据目录和日志目录,再切换回到ELK用户下
shell[elk@elk config]$ exit exit [root@elk ~]# mkdir -p /data/elk/{data,logs} [root@elk ~]# chown -R elk.elk /data/ [root@elk ~]# su - elk- 这里如果内存不太够用的话可以调整java占用内存的大小
shell[elk@elk config]$ pwd /usr/local/elasticsearch-7.3.0/config [elk@elk config]$ ls elasticsearch.keystore elasticsearch.yml.bak log4j2.properties roles.yml users_roles elasticsearch.yml jvm.options role_mapping.yml users [elk@elk config]$ vim jvm.options #修改以下 22行` -Xms1g `#意思是使用1G内存作为启动内存 23行` -Xms1g `#同上,但是内存并不会叠加 #这里建议设置不要超过自己全部内存的50%,如果这里设置的内存过大而自己的内存不足,则会导致OOM(内存溢出) #我在这里设置的是 22行` -Xms512m `#意思是设置512MB 23行` -Xms512m `#意思同上 -
启动es
shell[elk@elk config]$ /usr/local/elasticsearch-7.3.0/bin/elasticsearch #前台启动es #启动信息中出现started的时候,说明启动成功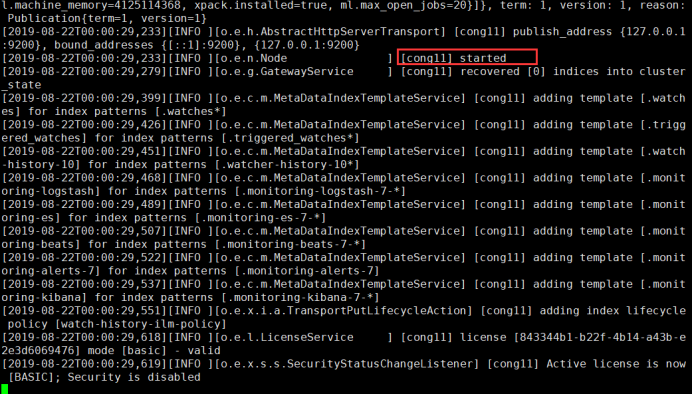 shell
shell#启动成功了,这时候说明咱们的配置文件无问题,就可以后台启动了 [elk@elk config]$ nohup /usr/local/elasticsearch-7.3.0/bin/elasticsearch & [1] 59288 #后台启动 -
检查端口
shell[elk@elk config]$ ss -anpt | grep 9200 LISTEN 0 128 [::]:9200 [::]:* users:(("java",pid=3058,fd=224))
- 查看进程
shell[elk@elk config]$ jps -m 3058 Elasticsearch -d 59386 Jps -m [elk@elk config]$
- 测试是否能够正常访问
shell[elk@elk config]$ curl localhost:9200
{
"name" : "elk-1",
"cluster_name" : "my-application",
"cluster_uuid" : "WpgtFTaGTo-pHj62w3-Qtw",
"version" : {
"number" : "7.3.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "de777fa",
"build_date" : "2019-07-24T18:30:11.767338Z",
"build_snapshot" : false,
"lucene_version" : "8.1.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
#访问测试 ok没问题
-
切换到root用户,设置开机启动脚本
shell[elk@elk config]$ exit exit [root@elk ~]# vim /etc/init.d/elasticsearch脚本内容如下:
shell#!/bin/sh #chkconfig: 2345 80 05 #description: elasticsearch export JAVA_BIN=/usr/local/jdk1.8.0_171/bin export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH case "$1" in start) su elk<<! cd /usr/local/elasticsearch-7.3.0/ ./bin/elasticsearch -d ! echo "elasticsearch startup" ;; stop) es_pid=`jps | grep Elasticsearch | awk '{print $1}'` kill -9 $es_pid echo "elasticsearch stopped" ;; restart) es_pid=`jps | grep Elasticsearch | awk '{print $1}'` kill -9 $es_pid echo "elasticsearch stopped" su elk<<! cd /usr/local/elasticsearch-7.3.0/ ./bin/elasticsearch -d ! echo "elasticsearch startup" ;; *) echo "start|stop|restart" ;; esac exit $? -
赋权、开机自启
shell[root@elk ~]# chmod +x /etc/init.d/elasticsearch #赋予执行权限 [root@elk ~]# chkconfig --add /etc/init.d/elasticsearch #设置开机自启 [root@elk ~]# systemctl restart elasticsearch.service #测试系统服务
3、安装logstash
shell[root@elk ~]# tar -xf logstash-7.3.0.tar.gz -C /usr/local/
#解压缩
[root@elk ~]# /usr/local/logstash-7.3.0/bin/logstash -e 'input {stdin{}} output {stdout{}}'
#测试
#当出现这个端口号的时候,说名启动成功,就可以输入一些东西来测试了
[root@elk ~]# Successfully started Logstash API endpoint {:port=>9600}
`hello world` #通过键盘输入的内容
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"@timestamp" => 2021-7-01T11:54:59.666Z,
"message" => "hello world",
"host" => "cong11",
"@version" => "1"
}
- 编辑配置文件
shell[root@elk ~]# vim /usr/local/logstash-7.3.0/config/logstash.conf
#内容如下
input {
file {
path => "/var/log/messages" #收集来源,这里从输入的文件路径收集系统日志。可以 用/var/log/*.log,/var/log/**/*.log,如果是/var/log则是/var/log/*.log
type => "messages_log" #通用选项. 用于激活过滤器
start_position => "beginning" #start_position 选择logstash开始读取文件的位置,begining或者end。默认是end,end从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了
}
}
filter { #过滤器插件,对事件执行中间处理、过滤,为空不过滤
}
output { #输出插件,将事件发送到特定目标
elasticsearch { #将事件发送到es,在es中存储日志
hosts => ["192.168.2.20:9200"]
index => "var-massages-%{+yyyy.MM.dd}" #index表示事件写入的索引。可以按照日志来创建索引,以便于删旧数据和按时间来搜索日志
}
stdout { codec => rubydebug } # stdout标准输出,输出到当前终端显示屏
}
- 还有很多的input/filter/output插件类型,可以参考官方文档来配置。
https://www.elastic.co/guide/en/logstash/current/index.html
- 最后做个软链接就可以了
shell[root@elk ~]# ln -s /usr/local/logstash-7.3.0/bin/* /usr/local/bin/
- 后台启动+开机自启
shell[root@elk ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/logstash.conf &
[1] 60984
#开机自启logstash+开机自动加载java环境
[root@elk ~]# echo "source /etc/profile" >>/etc/rc.local
[root@elk ~]# echo "nohup logstash -f /usr/local/logstash-7.3.0/config/logstash.conf &" >> /etc/rc.local
[root@elk ~]chmod +x /etc/rc.local
4、安装Kibana
- 解压缩Kibana压缩包
shell[root@elk ~]# tar -xf kibana-7.3.0-linux-x86_64.tar.gz -C /usr/local/
- 修改配置文件
shell#先备份一份
[root@elk ~]# cp /usr/local/kibana-7.3.0-linux-x86_64/config/kibana.yml{,bak}
#修改配置文件
[root@elk ~]# vim /usr/local/kibana-7.3.0-linux-x86_64/config/kibana.yml
2行` server.port: 5601 `#指定运行端口
7行` server.host: "192.168.2.20" `#指定服务运行主机ip
28行` elasticsearch.hosts: ["http://192.168.2.20:9200"] `#指定elasticsearch地址,多个服务器请用逗号隔开并用引号引起来
- 启动测试
shell[root@elk ~]# /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana --allow-root
#先在前台测试启动
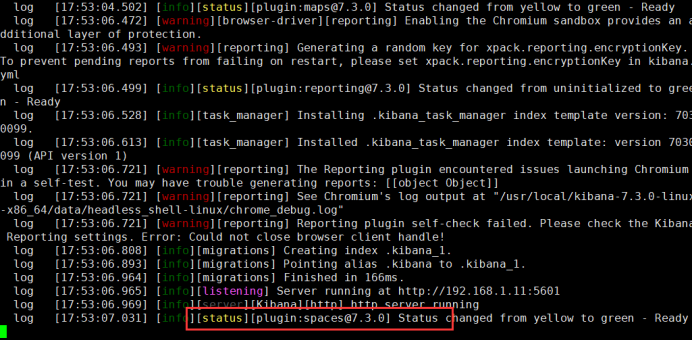
- 后台启动
shell[root@elk ~]# nohup /usr/local/kibana-7.3.0-linux-x86_64/bin/kibana &
[1] 61545
#端口启动成功
[root@elk ~]# ss -anpt | grep 5601
LISTEN 0 128 192.168.2.20:5601 *:* users:(("node",pid=52861,fd=26))
#配置开机自启
5、可视化
- 添加监控链接
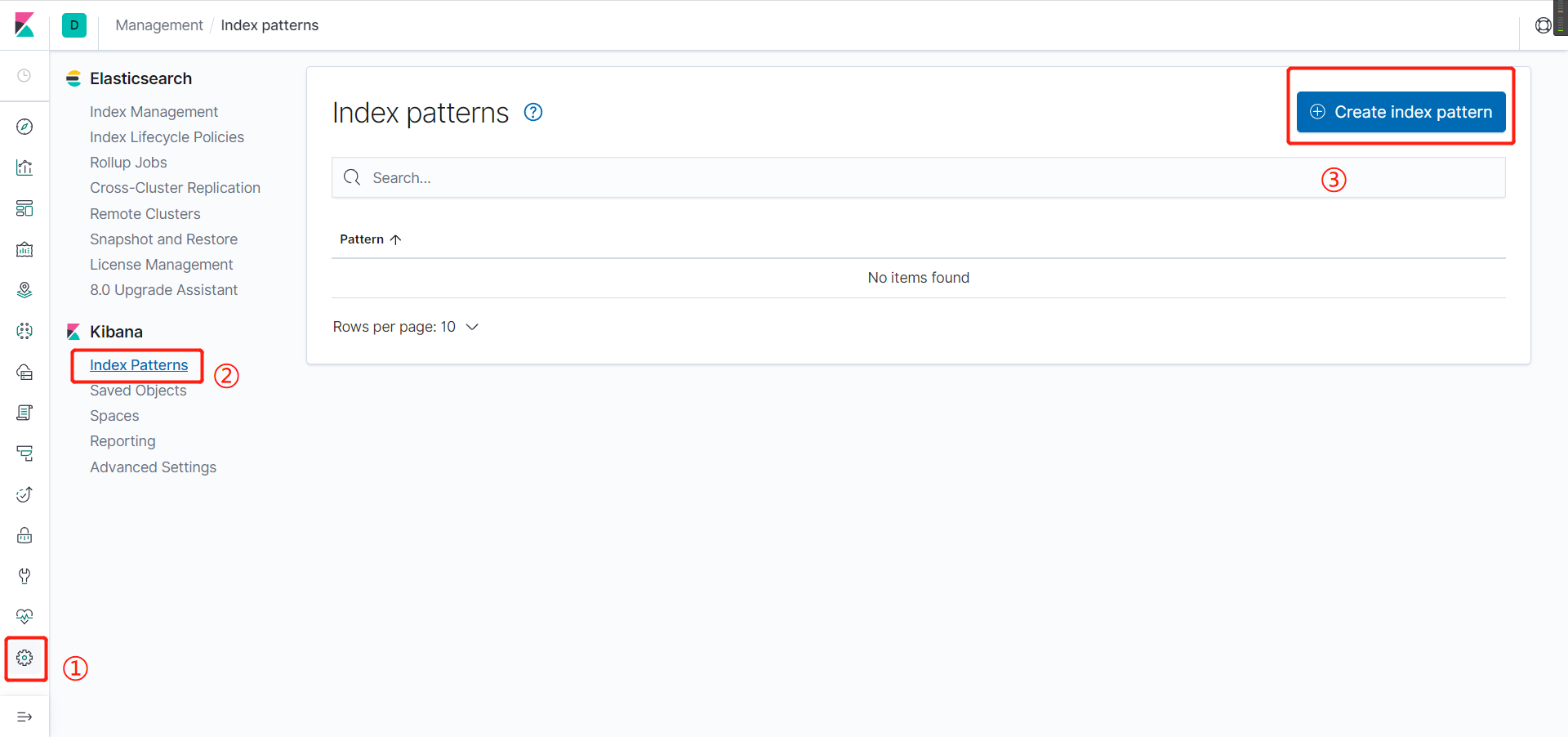
- 由于我已经监控好几天了,就出现了多个监控文件,这个不要管,只要出现 ==Success! Your index pattern matches 3 indices.== 就算监控有效
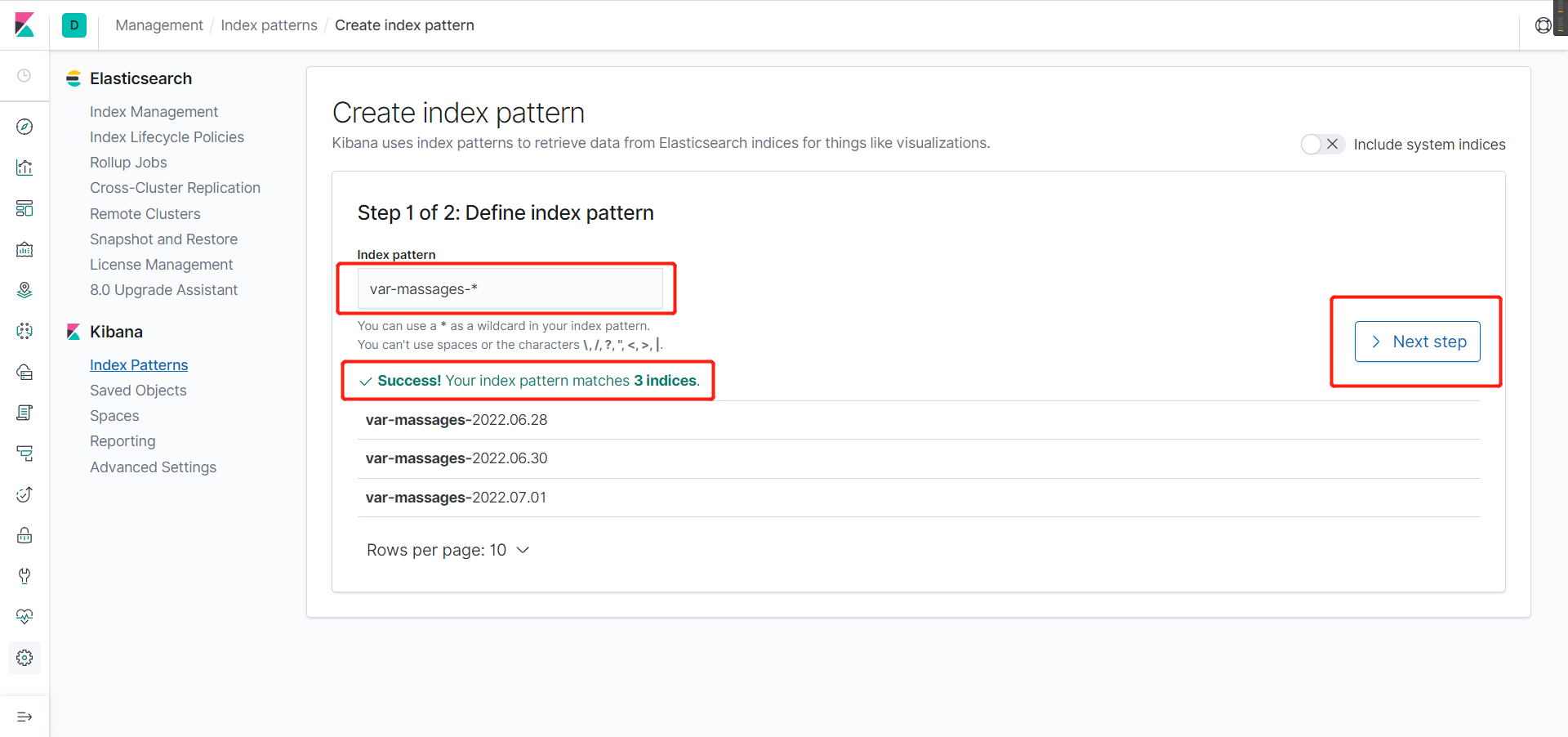
- 选择以时间为单位切割
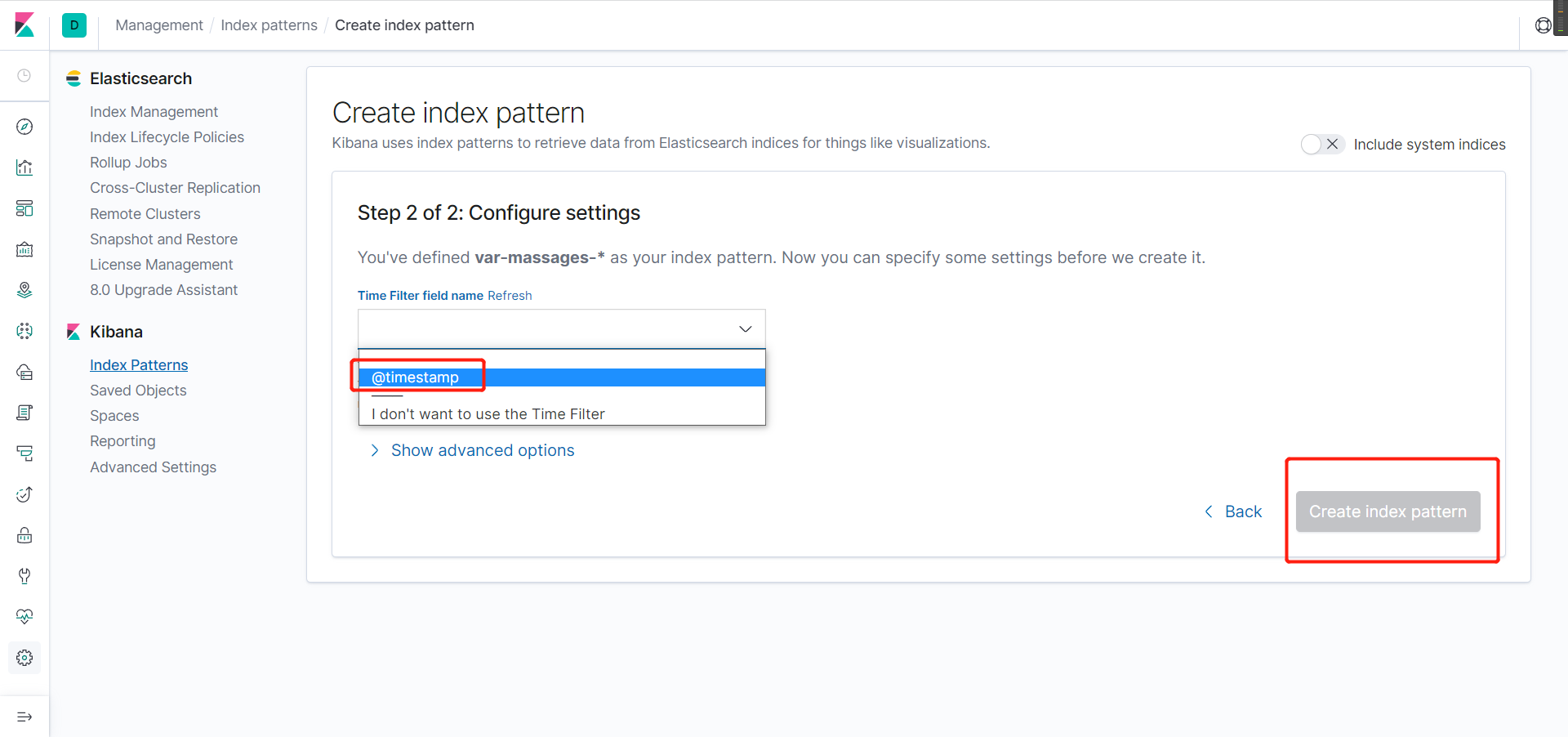
- 出现这个界面表示添加成功
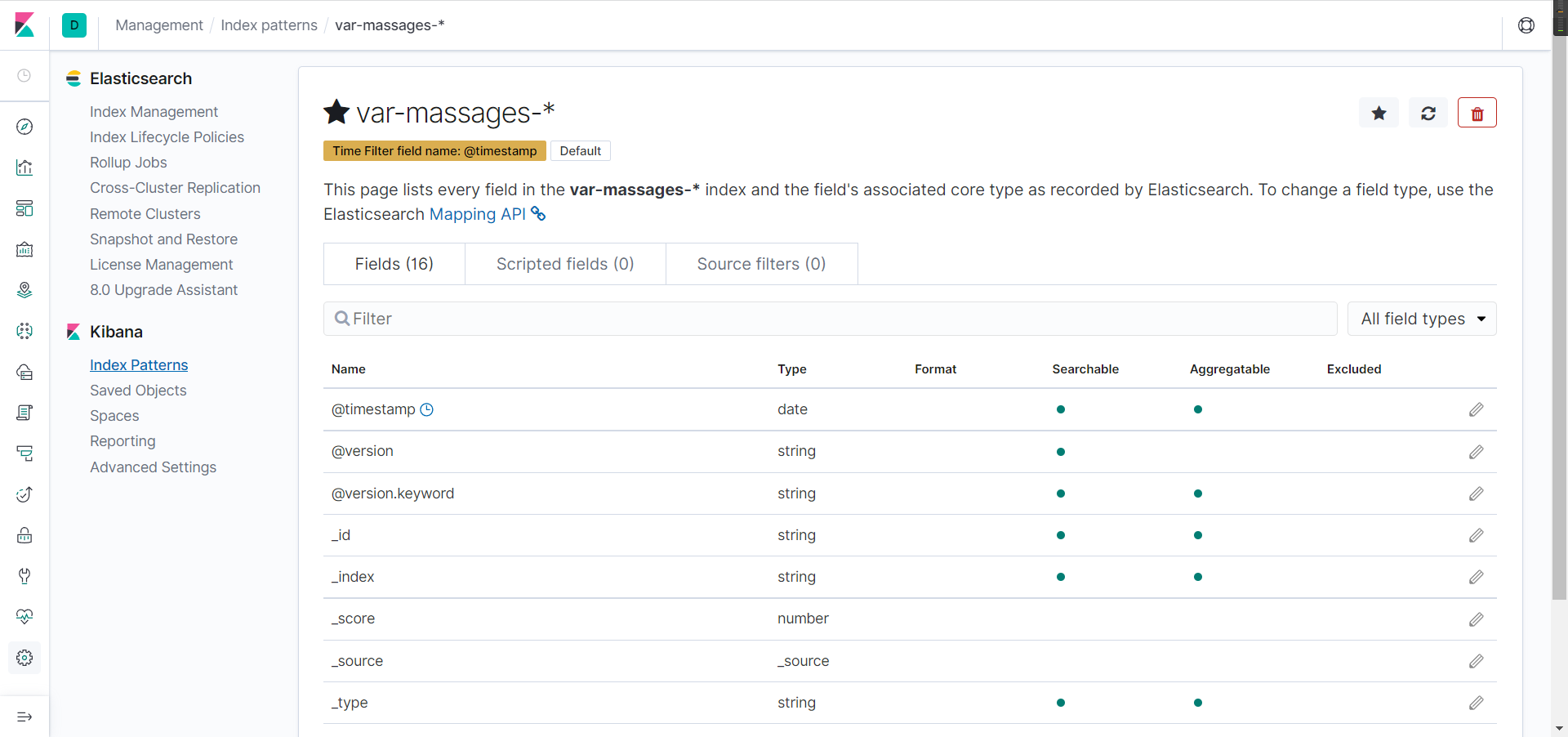
- 点红框这里就是可视化面板
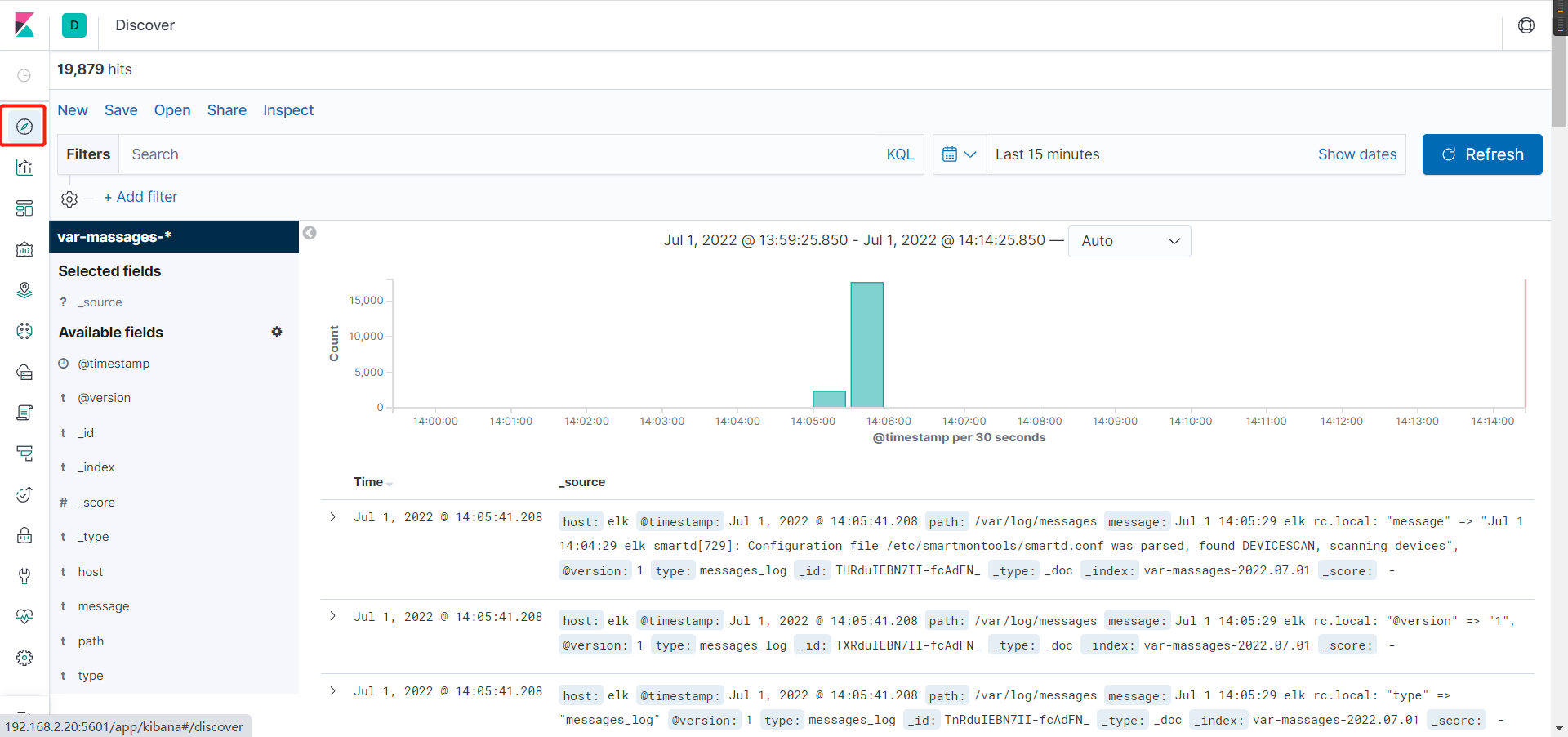
==做到这一步说明你的ELK平台部署完成。==
四、ELK+filebeat+nginx
这里是以ELK为基础,filebeat来收集服务日志,并将其发送给logstash服务,由logstash服务发给ES最后通过kibana展示到web
1、安装ELK、nginx —> 过程略
2、安装filebeat
1、上传filebeat安装包+解压缩安装包
shell[root@node3 ~]# ls filebeat-7.3.0-linux-x86_64.tar.gz [root@node3 ~]# [root@node3 ~]# tar -xf filebeat-7.3.0-linux-x86_64.tar.gz -C /usr/local/
2、修改配置文件
shell#先把filebeat的目录名改一下
[root@node3 ~]# cd /usr/local/
[root@node3 local]# ls
bin etc filebeat-7.3.0-linux-x86_64 games include jdk1.8.0_171 lib lib64 libexec sbin share src tomcat zabbix
[root@node3 local]# mv filebeat-7.3.0-linux-x86_64/ filebeat
[root@node3 local]# ls
bin etc filebeat games include jdk1.8.0_171 lib lib64 libexec sbin share src tomcat zabbix
[root@node3 local]#
#修改配置文件先拷贝一份
[root@node3 filebeat]# cp filebeat.yml{,.bak}
[root@node3 filebeat]# vim filebeat.yml
21行` - type: log `#设置类型,默认即可
24行` enabled: true `#enabled: true 该配置是否生效,如果改为false,将不收集该配置的日志
28行` - /usr/local/nginx/logs/*.log `#这里写的是nginx日志文件的完整路径,*.log表示所有log结尾的日志文件
#将148行`Elasticsearch output`块里面的全注释掉,因为这里的暂时用不到,这里使用的是`lgstash output`块
158行` output.logstash: `#取消注释,把日志放到logstash中
160行` hosts: ["192.168.2.20:5044"] `#这个地址是logstash的IP地址,端口是logstash监听的一个端口,后面会提到
184行` #logging.level: warning `#调整日志级别,前面的注释号不要去掉
3、测试启动
shell[root@node3 filebeat]# ./filebeat -e -c filebeat.yml
#这里只是测试运行,出现下方红框里的则代表可以成功运行
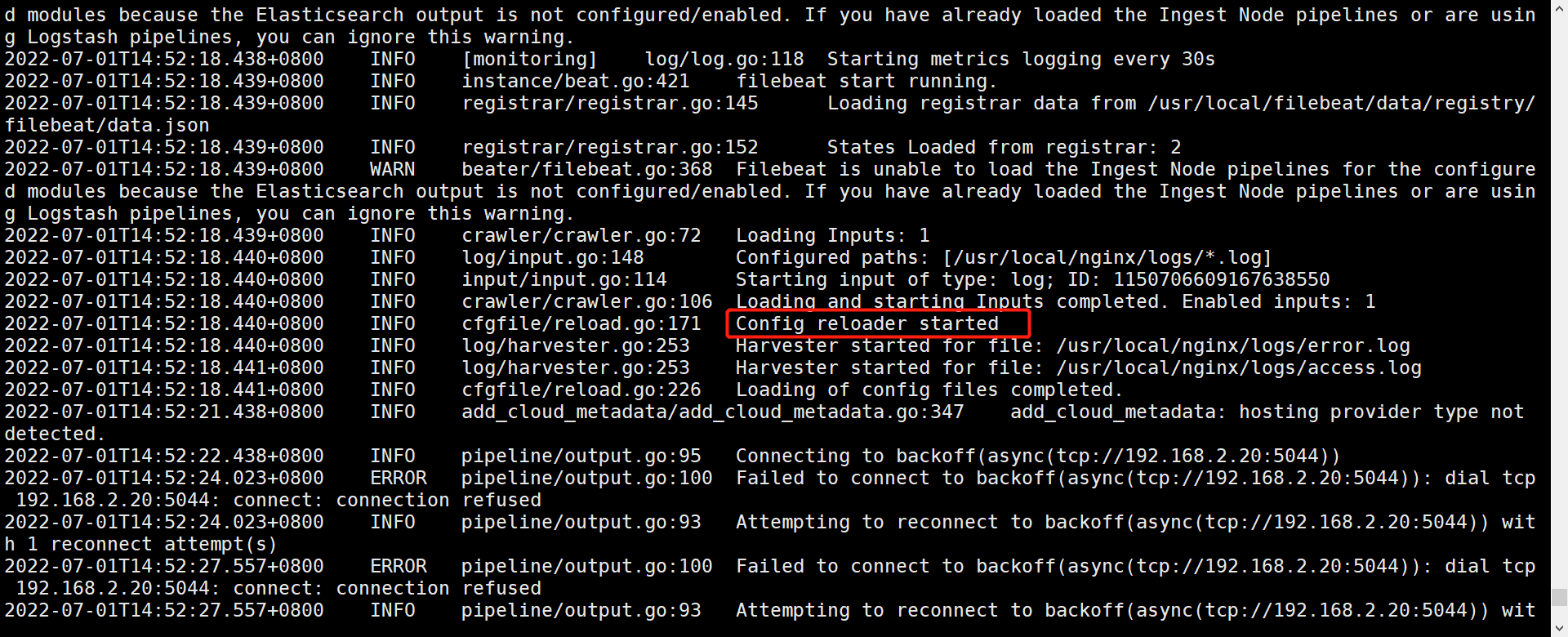
4、配置logstash
shell[root@elk ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.conf
#注意在哪台服务器上做的,内容如下
input{
beats { #从Elastic beats接收事件
codec => plain{charset => "UTF-8"} #设置编解码器为utf8
port => "5044" #要监听的端口
}
}
output {
stdout { #标准输出,把收集的日志在当前终端显示,方便测试服务连通性
codec => "rubydebug" #编解码器为rubydebug
}
elasticsearch { #把收集的日志发送给elasticsearch
hosts => [ "192.168.2.20:9200" ] # elasticsearch的服务器地址
index => "nginx-logs-%{+YYYY.MM.dd}" #创建索引
}
}
- 重新启动logstash+filebeat ==测试==
shell[root@elk ~]# jps
1683 Elasticsearch
2724 Jps
1093 Logstash
[root@elk ~]# kill -9 1093
[root@elk ~]# logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf
#启动filebeat
[root@node3 logs]# /usr/local/filebeat/filebeat -e -c filebeat.yml
- 测试无问题
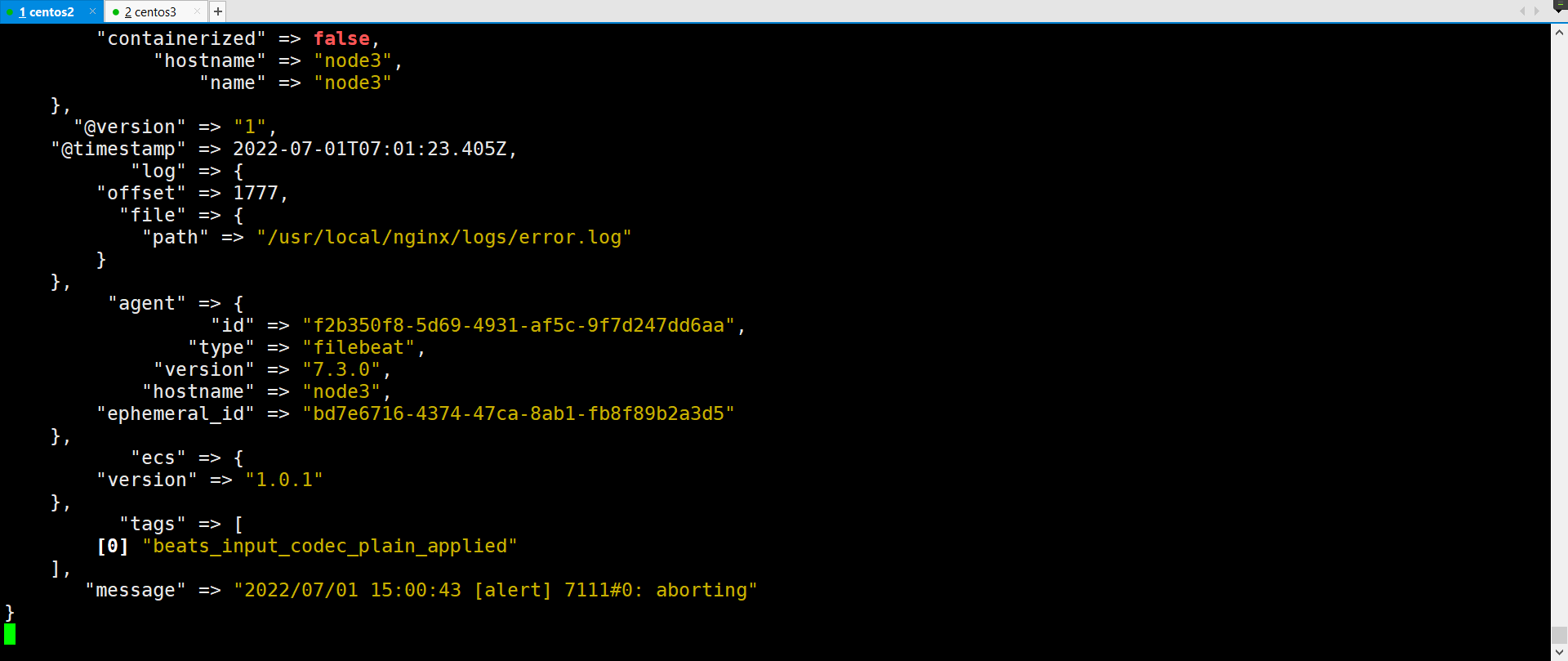
5、全部调位后台启动
shell#后台启动lostash
[root@elk ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf &
#后台启动filebeat
[root@node3 logs]# nohup /usr/local/filebeat/filebeat -e -c /usr/local/filebeat/filebeat.yml &
6、网页添加链接
==添加操作和上面的是一样的,这里就不一一演示了==
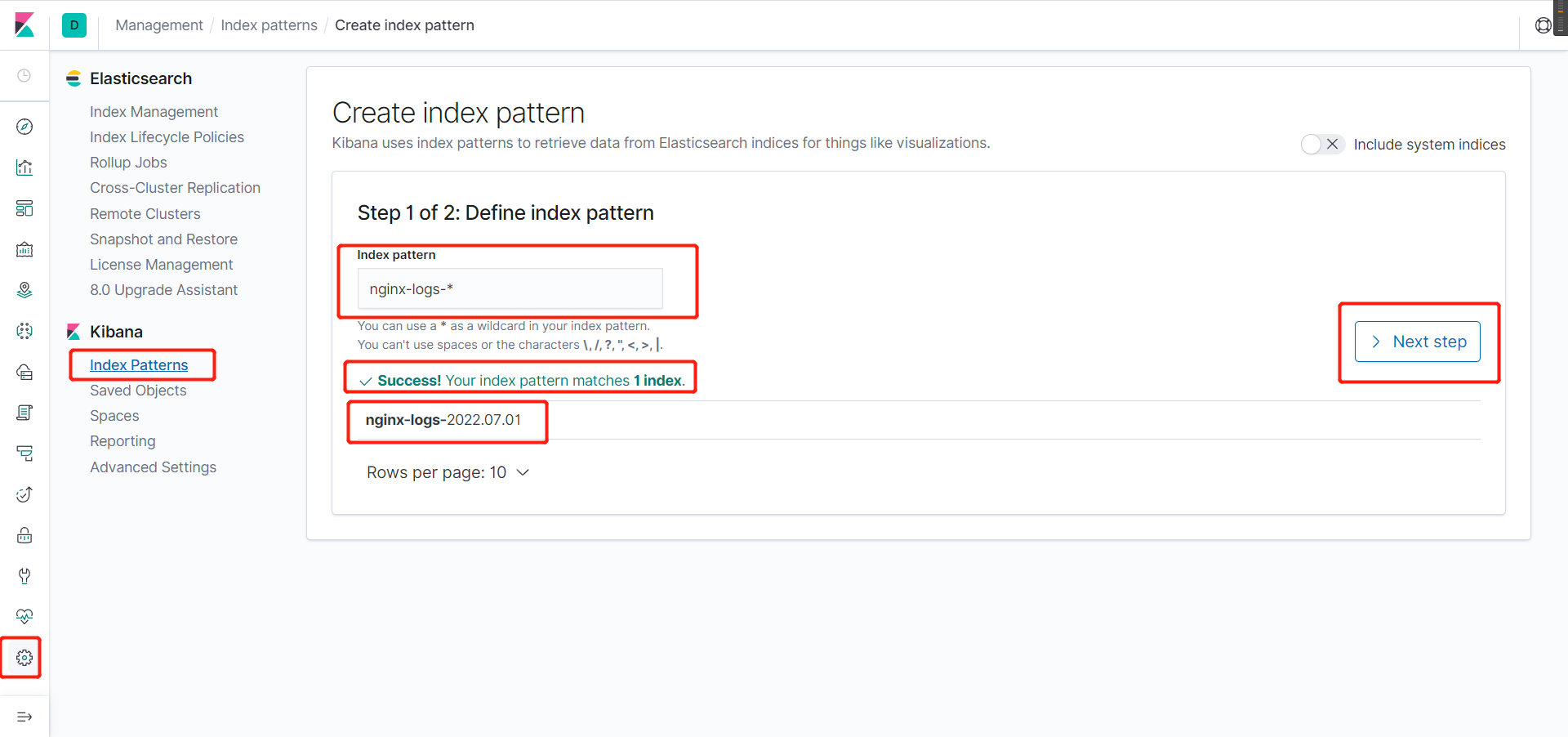
- 进入可视化面板后,选择nignx的日志链接
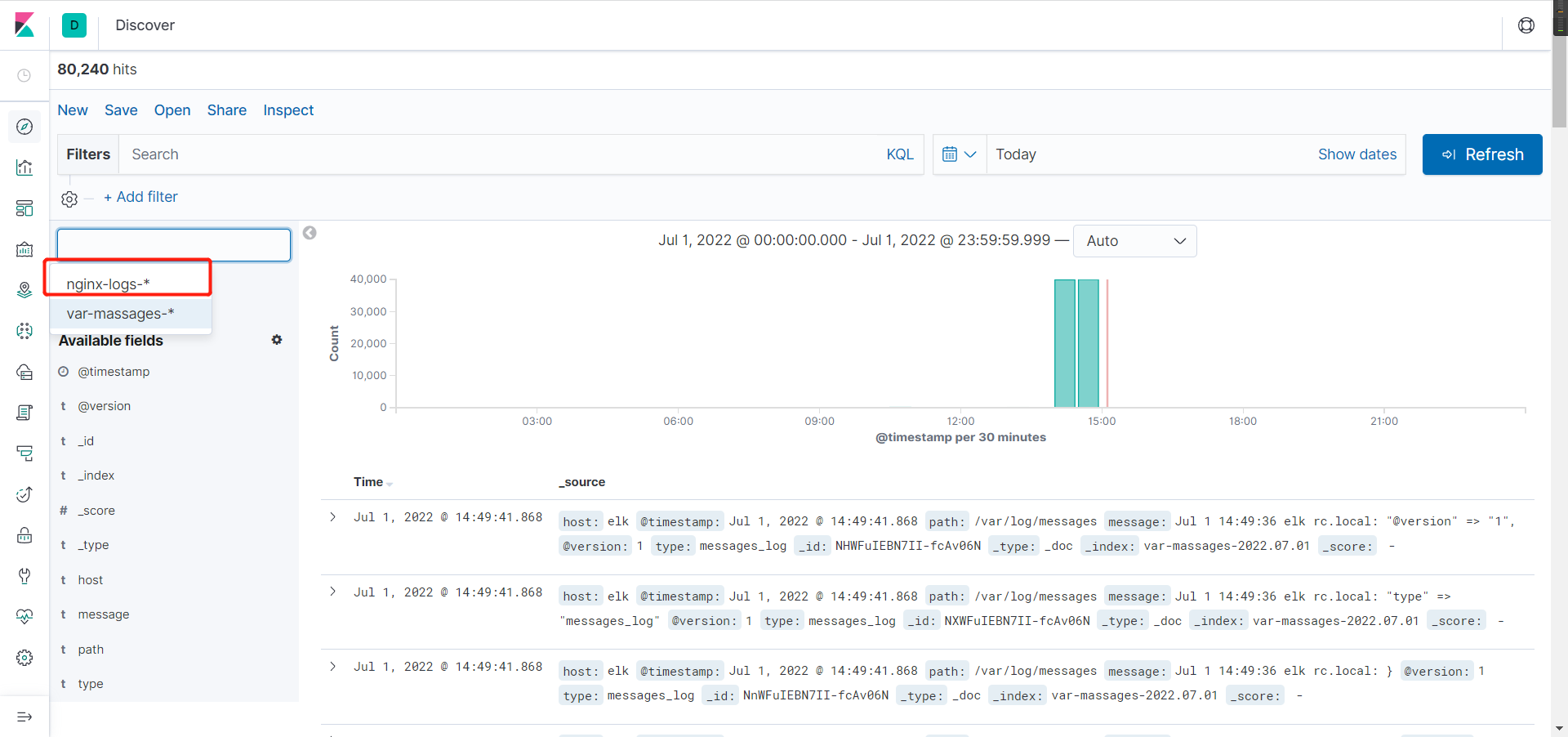
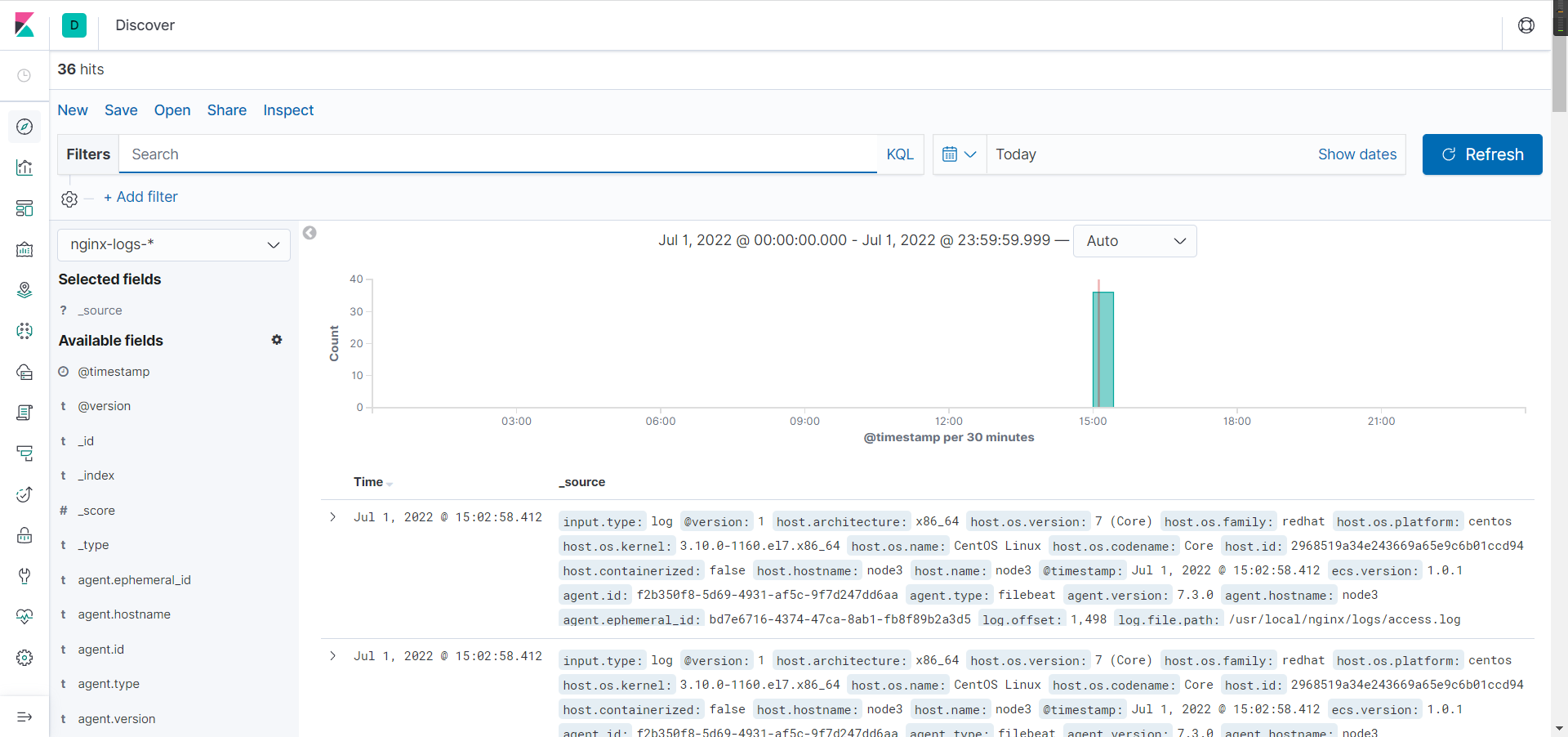
shellfor i in `seq 20` ;do curl 192.168.2.30 ;done
#访问某网站20次
五、ELK+kafka+filebeat+nginx
各配置文件编写方式
logstash主配置文件
shellinput {
#从……地方读取日志
}
filter {
#对读取到的日志进行处理(通过插件完成)
}
output {
#将日志输出到……(ES)
}
filebeat配置文件
shellfilebeat.inputs: - type: log paths: - /var/log/*.log fields: type: syslog output.logstash: hosts: ["localhost:5044"]
六、ELK-logstash收集日志写入redis#
用一台服务器部署redis服务,专门用于日志缓存使用,一般用于web服务器产生大量日志的场景。
这里是使用一台专门用于部署redis ,一台专门部署了logstash,在linux-elk1ELK集群上面进行日志收集存到了redis服务器上面,然后通过专门的logstash服务器去redis服务器里面取出数据在放到kibana上面进行展示
1、部署redis
[root@linux-redis ~]# wget http://download.redis.io/releases/redis-5.0.0.tar.gz [root@linux-redis ~]# tar -xvzf redis-5.0.0.tar.gz [root@linux-redis ~]# mv redis-5.0.0 /usr/local/src/ [root@linux-redis ~]# ln -sv /usr/local/src/redis-5.0.0 /usr/local/redis "/usr/local/redis" -> "/usr/local/src/redis-5.0.0" [root@linux-redis ~]# cd /usr/local/redis/ [root@linux-redis ~]# make distclean [root@linux-redis ~]# make
2、配置redis
[root@linux-redis redis]# vim redis.conf daemonize yes bind 192.168.1.30 requirepass 123321 [root@linux-redis redis]# cp /usr/local/redis/src/redis-server /usr/bin/ [root@linux-redis redis]# cp /usr/local/redis/src/redis-cli /usr/bin/ [root@linux-redis redis]# redis-server /usr/local/redis/redis.conf 4007:C 10 Jul 2019 12:24:30.367 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 4007:C 10 Jul 2019 12:24:30.367 # Redis version=5.0.0, bits=64, commit=00000000, modified=0, pid=4007, just started 4007:C 10 Jul 2019 12:24:30.367 # Configuration loaded [root@linux-redis redis]# netstat -nlutp |grep 6379 tcp 0 0 192.168.1.30:6379 0.0.0.0:* LISTEN 4008/redis-server 1
3、测试redis
[root@linux-redis redis]# redis-cli -h 192.168.1.30 192.168.1.30:6379> AUTH 123321 OK 192.168.1.30:6379> ping PONG 192.168.1.30:6379> KEYS * (empty list or set) 192.168.1.30:6379> quit
4、配置logstash将日志写入redis
将系统日志的通过logstash收集之后写入redis,然后通过另外的logstash将redis服务器的数据取出来。
配置logstash的配置文件
[root@linux-elk1 ~]# vim /etc/logstash/conf.d/system.conf input { file { path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "2" } } output { if [type] == "systemlog" { redis { data_type => "list" host => "192.168.1.30" password => "123321" port => "6379" db => "0" key => "systemlog" } } }
检查logstash配置语法是否正确
[root@linux-elk1 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/system.conf -t WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console [WARN ] 2019-07-10 14:46:46.324 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified Configuration OK [root@linux-elk1 ~]# systemctl restart logstash
写入messages日志测试
[root@linux-elk1 ~]# echo "redis-test" >> /var/log/messages [root@linux-elk1 ~]# echo "systemlog" >> /var/log/messages
登录redis进行查看
[root@linux-redis ~]# redis-cli -h 192.168.1.30 192.168.1.30:6379> AUTH 123321 OK 192.168.1.30:6379> SELECT 0 OK 192.168.1.30:6379> KEYS * 1) "systemlog" 192.168.1.30:6379> LLEN systemlog (integer) 126
5、配置logstash从redis中取出数据到elasticsearch
配置专门logstash服务器从redis服务器读取指定的key的数据,并写入到elasticsearch
编辑logstash配置文件
[root@logstash ~]# vim /etc/logstash/conf.d/redis-read.conf input { redis { data_type => "list" host => "192.168.1.30" password => "123321" port => "6379" db => "0" key => "systemlog" } } output { elasticsearch { hosts => ["192.168.1.31:9200"] index => "redis-systemlog-%{+YYYY.MM.dd}" } }
测试logstash配置是否正确
[root@logstash ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis-read.conf -t OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console [INFO ] 2019-07-10 16:41:50.576 [main] writabledirectory - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"} [INFO ] 2019-07-10 16:41:50.649 [main] writabledirectory - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"} [WARN ] 2019-07-10 16:41:51.498 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified Configuration OK [root@logstash ~]# systemctl restart logstash
验证redis的数据是否被取出
[root@linux-redis ~]# redis-cli -h 192.168.1.30 192.168.1.30:6379> AUTH 123321 OK 192.168.1.30:6379> SELECT 0 OK 192.168.1.30:6379> KEYS * (empty list or set) #这里数据已经为空 192.168.1.30:6379> SELECT 1 OK 192.168.1.30:6379[1]> KEYS * (empty list or set) #这里数据已经为空
6、head插件上验证数据

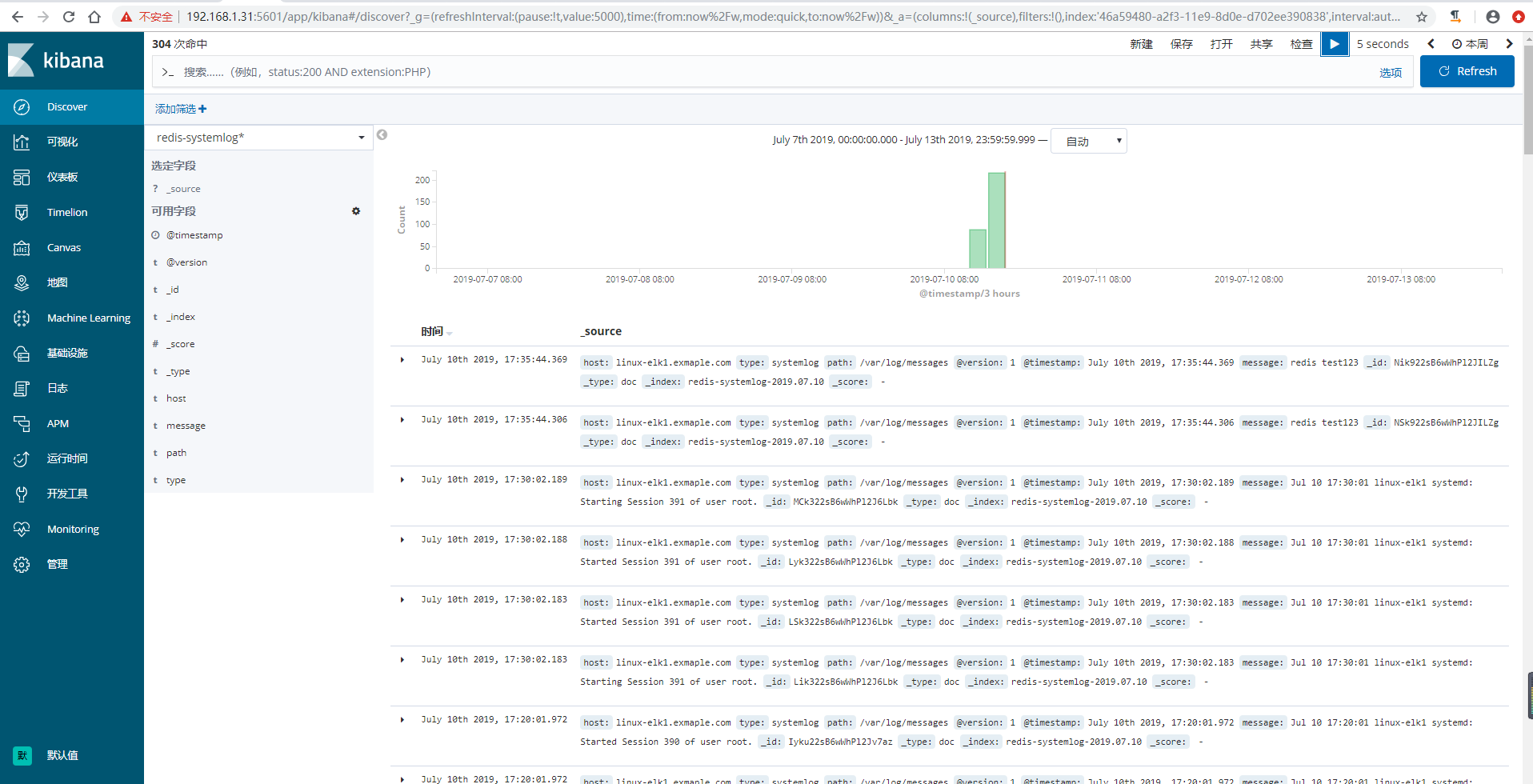
7、kibana界面创建索引模式并查看数据
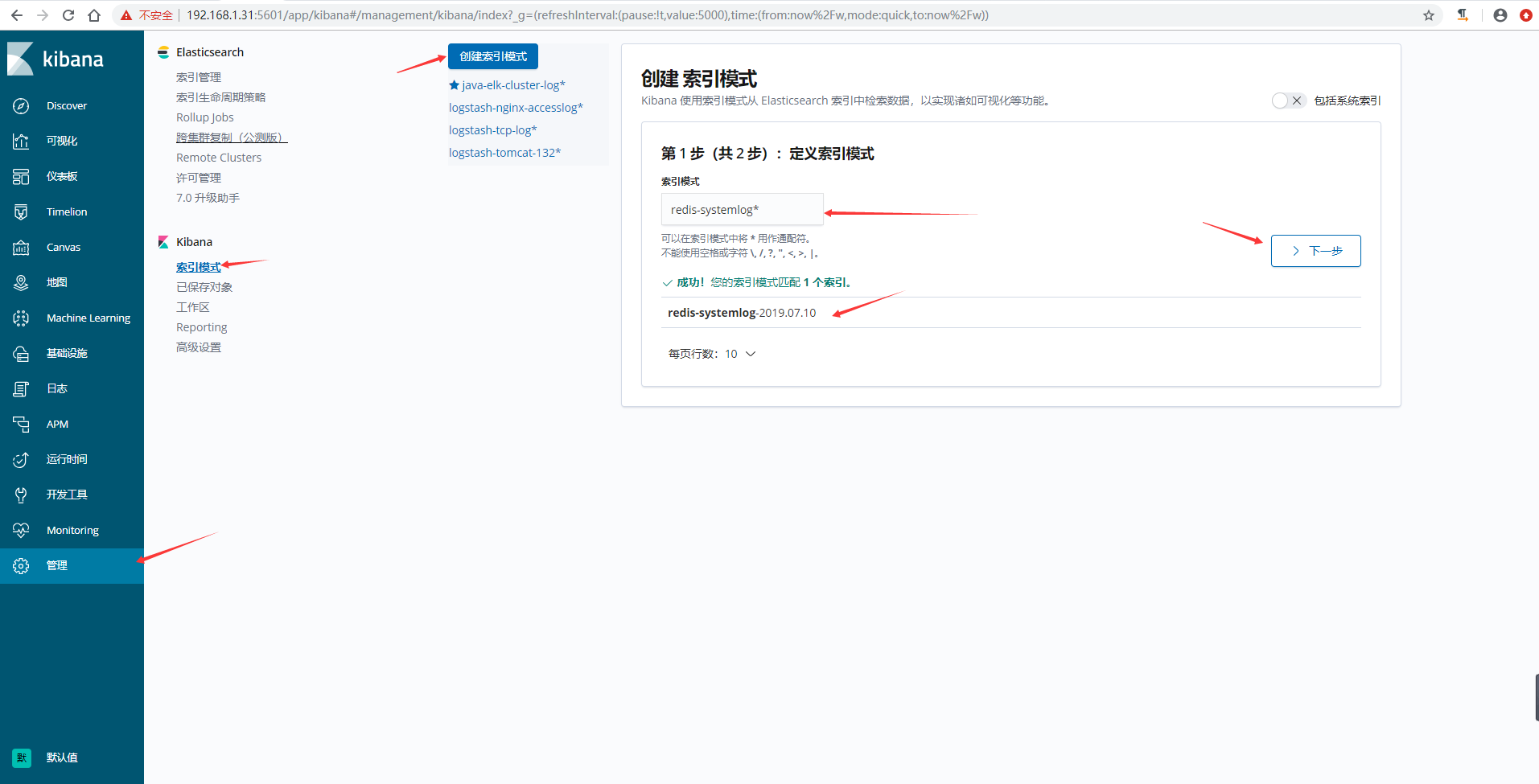
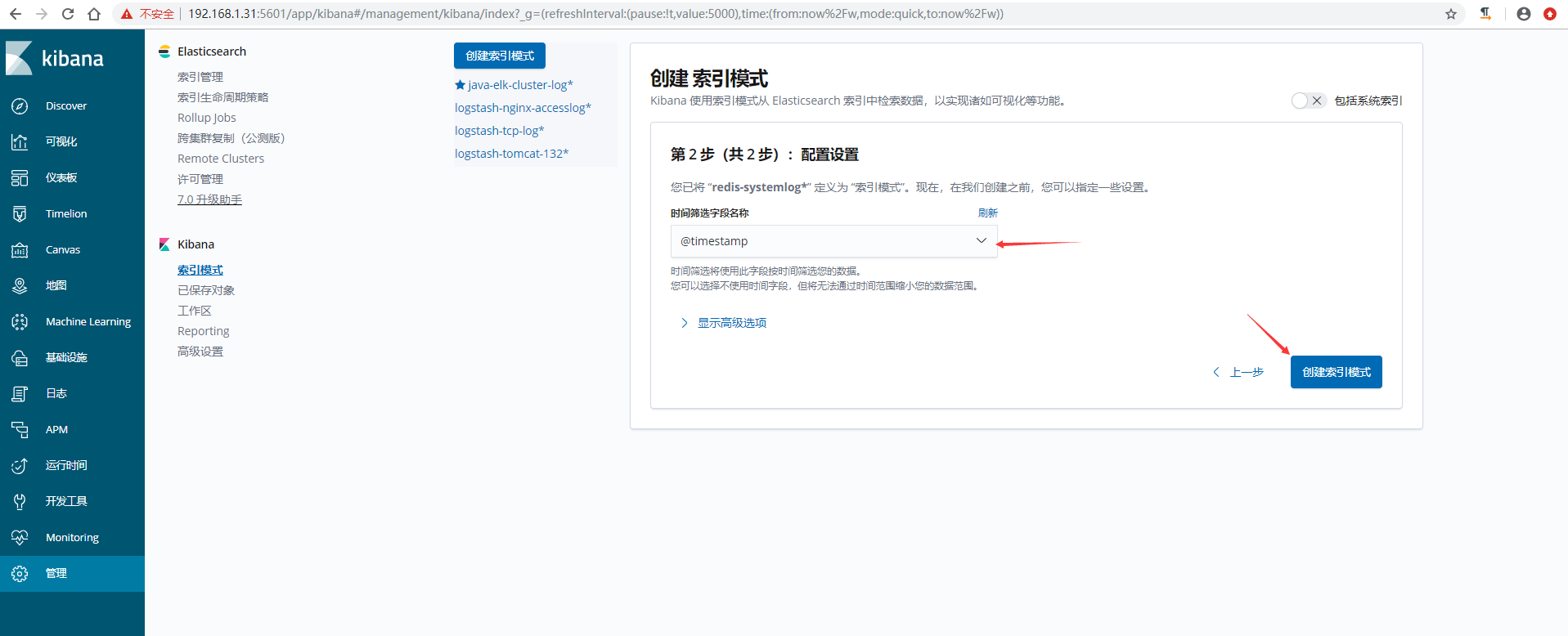


本文作者:ZYW
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 ™ 许可协议。转载请注明出处!